When working with data processing in Java, choosing the right file format for storing and transmitting the data is crucial. Each format (such as CSV, JSON, or Parquet) has its particular advantages and disadvantages, as they are specifically designed to cater to different use cases. In this article, I’ll focus on the AVRO file format provided by Apache Avro, a powerful data serialization framework widely used for streaming binary files. I’ll cover the main features of Avro and why/when/how to use it for serialize and deserialize your data files in Java.

Introduction
Different data formats excel in specific use cases, such as business intelligence, network communication, web applications, batch processing, or stream processing. Understanding their strengths and leveraging their specific features is essential when choosing one or the other. Making an informed decision is a major concern of developers, and of software architects and data engineers in particular.
Apache Avro is a powerful data serialization framework that provides many useful features. It uses the AVRO file format, which is a compact binary format suitable for evolving data schemas. For example, it supports schema enforcement and schema transformations, which are essential for data integrity and compatibility. The AVRO file format1 is ideal in case of ETL operations where we need to query all the columns in a table because of the structure and size of the data its data model.
The following table compares AVRO w.r.t the most popular data formats:
| Format | Data | Data Type | Schema Enforcement | Schema Evolution | Storage Type | OLAP/OLTP | Splittable | Stream | Typed | Ecosystems |
|---|---|---|---|---|---|---|---|---|---|---|
| AVRO | metadata in JSON | yes | yes | yes | row | OLTP | yes | yes | no | Big Data and Streaming |
| CSV | text | no | no (minimal with header) | no | row | OLTP | yes in its simpliest form | yes | no | popular everywhere for its simplicity |
| JSON | text | yes | external for validation | yes | row | OLTP | yes with JSON lines | yes | no | API and web |
| XML | text | no | external for validation | yes | row | OLTP | no | no | no | enterprise |
| Protobuf | data in binary | yes | yes | no | row | OLTP | no | yes | yes | RPC and Kubernetes |
| Parquet | text | yes | yes | yes | column | OLAP | yes | no | no | Big Data and Business Intelligence |
| ORC | binary | yes | yes | no | column | OLAP | yes | no | no | Big Data and Business Intelligence |
Why using Apache Avro?
The Avro data serialization system provides a rich data structures in a compact, fast, binary data format. It is used in popular big data frameworks such as Spark, Kafka, and Hadoop. AVRO is a row-based, schema-based format that allows defining a data schema using JSON. In the case of Java, the schema can be compiled into Java classes that can be used to read and write AVRO binary data. This way, developers can confidently work with data in their applications, knowing that it aligns with the defined schema and can be accurately interpreted by data consumers. The use of a data schema improves data reliability, interoperability, and processing efficiency.
Here are some advantages of using Avro instead of other data file formats:
Schema Enforcement: Avro provides robust schema enforcement capabilities, ensuring data validity and facilitating seamless data integration and processing. Schemas can be associated with the data or provided separately, guaranteeing that the dataset adheres to the specified schema and giving additional information about its structure, types, and formats. Avro’s schema enforcement eases encryption/decryption of content, enhancing data security and integrity during storage and transmission.
Schema Evolution: Avro supports schema evolution, which allows changing data schemas over time while maintaining backward compatibility. Developers can add, remove, or modify fields in the schema without requiring all consumers or producers to be updated simultaneously. This flexibility is especially useful in scenarios where different components of a system are developed and deployed independently.
Compact Binary Format: Avro uses a compact binary encoding, which results in smaller file sizes compared to other formats like JSON or XML. This makes Avro an efficient choice for data storage and transmission, reducing storage costs and improving performance.
Fast Serialization and Deserialization: Avro’s binary encoding is designed for efficient serialization and deserialization. It has a smaller memory footprint and faster processing speed compared to text-based formats. This makes it suitable for high-throughput data processing and streaming applications.
Language Independence: Avro provides support for multiple programming languages, allowing you to work with Avro data in different languages seamlessly. Avro schemas can be defined using JSON, and Avro provides code generation utilities to generate language-specific classes from the schema. This makes it easy to integrate Avro into existing systems regardless of the programming language being used.
Data Compression: Avro supports built-in compression for its data files, which can further reduce the file sizes. You can choose from different compression codecs such as Snappy, Deflate, or Bzip2, depending on your specific requirements. This feature is particularly beneficial when working with large datasets or when network bandwidth is limited.
Rich Data Types: Avro supports a wide range of data types, including primitive types, complex types (arrays, maps, records), and even user-defined types. This flexibility allows representing complex data structures accurately, making Avro suitable for modeling diverse datasets.
Interoperability: Avro is designed for interoperability, enabling data exchange between different systems and platforms. AVRO data files can be easily read and processed by systems implemented in different languages, making it a versatile choice for distributed architectures and data integration scenarios.
In summary, Apache Avro provides a combination of schema evolution, compactness, performance, language independence, and interoperability, making it a powerful data serialization and storage solution for a wide range of use cases.
How does it work?
Avro works well in architectures implementing the Producer-Consumer pattern. The producer manipulates and writes data to a file, and the consumer reads data from the file. This is a common pattern in Big Data and Streaming applications.
Here’s a diagram of a typical serialization/deserialization the Avro workflow involving a producer and a consumer:
%%{init: {'theme':'base'}}%%
flowchart TB;
a(["Data"]) --> |.json| x[Avro Schema]
x --> |.avsc| y[Serialization]
y --> |.avro| s[Network]
s --> |.avro| q[Consumer]
q --> |.avro| z[Deserialization]
z --> |.class| t[Java Objects]
t --> f[Producer]
f --> a
Creating the Avro schema
Avro schemas are defined using JSON. They can be defined in a separate file or embedded in the code. As a best practice, it is recommended to define the schema in a separate file and use code generation tools to generate language-specific classes from the schema.
Here’s an example of an Avro schema file with various data types defining a Person object:
{
"type": "record",
"name": "Person",
"fields": [
{ "name": "id", "type": "int" },
{ "name": "name", "type": "string" },
{ "name": "age", "type": "int" },
{ "name": "height", "type": "float" },
{ "name": "isEmployed", "type": "boolean" },
{ "name": "address", "type": "string" },
{ "name": "phoneNumbers", "type": {
"type": "array",
"items": "string"
}},
{ "name": "salary", "type": ["null", "float"], "default": null },
{ "name": "birthDate", "type": {
"type": "record",
"name": "Date",
"fields": [
{ "name": "year", "type": "int" },
{ "name": "month", "type": "int" },
{ "name": "day", "type": "int" }
]
}},
{ "name": "skills", "type": {
"type": "map",
"values": "string"
}}
]
}
In the previous example, the Person record has the following fields:
id(integer): Represents the unique identifier for a person.name(string): Represents the person’s name.age(integer): Represents the person’s age.height(float): Represents the person’s height.isEmployed(boolean): Represents whether the person is currently employed or not.address(string): Represents the person’s address.phoneNumbers(array of strings): Represents the person’s phone numbers.salary(nullable float): Represents the person’s salary, which can be null.birthDate(nested record): Represents the person’s birth date, consisting of year, month, and day fields.skills(map of strings): Represents the person’s skills, where the keys are skill names and the values are skill levels.
This example covers various Avro data types, including primitive types (int, float, string, boolean), complex types (array, record, map), and nullable types using the union type (["null", "float"]).
Using the schema in Java
Once you have defined the schema, you can use the Avro Maven plugin to generate Java classes from the previous schema.
First, add the following dependency in the pom.xml file:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.1</version>
</dependency>
Second, add the Avro Maven plugin (for performing code generation):
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.11.1</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
After running the plugin, the following Java classes will be generated: Person.java and Date.java.
Figure 1 shows the class diagram for the Person class:
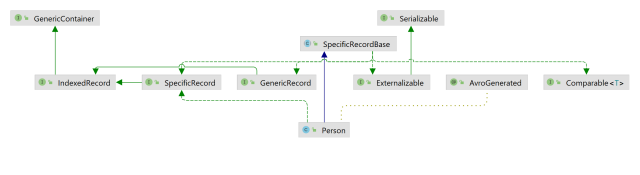
Person object generated with Apache Avro.Figure 2 shows the auto-generated class members in the Person class :

Person object generated with Apache Avro.Serializing/Deserializing Java objects
Now that we have the schema and the Java classes, we can use them to serialize and deserialize objects.
Let’s say that we want to serialize and deserialize a list of Person objects using Avro.
The following code snippet shows what this would look like:
public static void main(String[] args) throws IOException {
// A list of Person objects
List<Person> personList = List.of(
new Person(1, "John", 25, 175.5f, true, "123 Main St", List.of("555-1111", "555-2222"), null, new Date(1998, 6, 15), Map.of("programming", "Java", "design", "Photoshop")),
new Person(2, "Alice", 30, 160.0f, false, "456 Elm St", List.of("555-3333"), 5000.0f, new Date(1993, 9, 21), Map.of("writing", "Copywriting", "marketing", "SEO")),
new Person(3, "Bob", 40, 185.3f, true, "789 Oak St", List.of("555-4444", "555-5555", "555-6666"), 8000.0f, new Date(1983, 3, 8), Map.of("programming", "Python", "data analysis", "SQL"))
);
// Serialize persons to disk
File personsListSerializedFile = new File("persons.avro");
serializePersons(personList, personsListSerializedFile);
// Deserialize persons from disk
deserializePersons(personsListSerializedFile).stream().map(Person::toString).forEach(System.out::println);
}Here’s the implementation of the method serializePersons:
/**
* Serialize a list of Persons to disk using Avro and write to the specified file (.avro).
* @param personList List of Persons
* @param personListSerializedFile File to write to
* @throws IOException If there is an error writing to the file
*/
private static void serializePersons(List<Person> personList, File personListSerializedFile) throws IOException {
// We create a DatumWriter, which converts Java objects into an in-memory serialized format.
// The SpecificDatumWriter class is used with generated classes and extracts the schema from the specified generated type.
DatumWriter<Person> datumWriter = new SpecificDatumWriter<>(Person.class);
// Next we create a DataFileWriter, which writes the serialized records, as well as the schema, to the file specified in the dataFileWriter.create() call.
// We write our persons to the file via calls to the dataFileWriter.append method. When we are done writing, we close the data file.
DataFileWriter<Person> dataFileWriter = new DataFileWriter<>(datumWriter);
dataFileWriter.create(personList.get(0).getSchema(), personListSerializedFile);
personList.forEach(person -> {
try {
dataFileWriter.append(person);
} catch (IOException e) {
System.err.println("Error writing person with id: " + person.getId());
}
});
dataFileWriter.close();
}The previous code produces a file persons.avro, which contains the serialized objects.
If we open the file in a text editor, we can see that it contains the serialized objects in binary format.
Here’s the method deserializePersons, which deserializes the file into a ArrayList of Person objects:
/**
* Deserialize a list of Person objects from disk using Avro.
* @param personListSerializedFile File to read from (.avro)
* @return List of Person
* @throws IOException If there is an error reading from the file
*/
private static List<Person> deserializePersons(File personListSerializedFile) throws IOException {
DatumReader<Person> personDatumReader = new SpecificDatumReader<>(Person.class);
DataFileReader<Person> dataFileReader = new DataFileReader<>(personListSerializedFile, personDatumReader);
Person person = null;
List<Person> persons = new ArrayList<>();
// Reuse person object by passing it to next(). This saves us from allocating and garbage collecting many objects for files with many items.
while (dataFileReader.hasNext()) {
person = dataFileReader.next(person);
persons.add(person);
}
dataFileReader.close();
return persons;
}Conclusion
In this article, we have seen how to use Apache Avro to serialize and deserialize objects in Java. When it comes to fast binary data transfer, Apache Avro offers compelling advantages. Its support for schema evolution, compact binary format, fast serialization/deserialization, language independence, and interoperability make it a valuable tool for storing and processing data efficiently. By leveraging the benefits of Apache Avro, developers can streamline their data processing workflows and improve overall system performance.
References
- Avro examples
 Apache Avro official documentation
Apache Avro official documentation- Guide to Apache Avro
- Guide to Spring Cloud Stream with Kafka, Apache Avro and Confluent Schema Registry
Further Reading
- CSV vs Parquet vs Avro: Choosing the Right Tool for the Right Job
- Big Data File Formats
- Comparaison of different file formats in Big Data
Footnotes
In this article we refer to “Avro” as the Apache Avro project, and “AVRO” as the Avro data serialization format. ↩


