After reading the paper “Is Static Analysis Able to Identify Unnecessary Source Code?” about the negative impact of unnecessary code in the software industry, I felt stuck with the many different (but very related) concepts around this topic. One can think that unnecessary code is all code that is not needed for an application to run correctly. However, the fact is that the concept is more complicated than it seems, and sometimes it is not very easy to understand what unnecessary means in this context. For example, there is a slight (but quite important) difference between what we know as dead code (code that will never be used) and unnecessary code (code that can be used or not, but definitely is not required for the application).
Thus, to put all the important related concepts together, I made the following diagram:
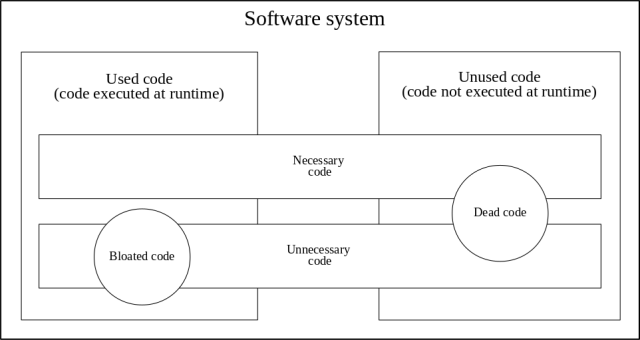
Le me clarify each concept in the diagram presented before:
- Used code: code that is executed at runtime, within a specific time in a production environment. It depends directly on the entry point of the application that is being considered.
- Unused code: code that is not being executed at runtime within a specific time period in a production environment.
- Dead code: code that is not reachable in the control flow graph from any entry vertex from the application code. Therefore, it cannot be executed during runtime, and hence, dead code is always unused code.
- Bloated code: code that is perceived as unnecessarily long, slow, or otherwise wasteful of resources. It generally refers to source code size or binary file size. The term “bloatware” refers to software that has become bloated through inefficiency or accretion of features.
- Unnecessary code: code that can be deleted from the codebase without affecting the expected functionality of the software project.
Unnecessary code is not the same as dead code, because unnecessary code can still be reachable in the control flow. So, dead code can be unnecessary but does not necessarily need to be. For example, the implementation of a new feature that has not been yet integrated into the software system and is not reachable. Unused code is also not necessarily unnecessary code. For instance, error handling, recovery, or migration code is considered as useful even if it is not executed. The same applies for test code, which is not executed in a deployed production environment.
Unnecessary code usually is very hard to detect, and even more difficult to remove for sure. Just imagine a scenery in which a developer must decide between removing a very old piece of code that is likely unneeded (but she knows that it works) or keep it safe (just for the care of not breaking something). Probably the developer will choose not to make the change.
For the above reason, modern applications are becoming very bloated nowadays. \Developers commonly do not care about the size or the resources consumed at runtime, as long as their apps work correctly. The automatic detection and removal of unnecessary code is a current necessity for the software industry.
Accordingly, there are two main approaches to detect unnecessary code, involving both static and dynamic code analysis:
Analytical: can reliably discriminate between necessary and unnecessary code pieces. Examples are dead code analysis (a piece of code is not reachable and therefore unnecessary), reachability analysis for project files (a source file is not included in any project file, and therefore its code is unreachable and unnecessary) and platform-incompatibility analysis (a piece of code does not support the execution platform and is therefore not executable and unnecessary, for example, when code does not support Unicode on a Unicode-based platform).
Heuristical: uses one or more heuristics to discriminate between necessary and unnecessary code pieces.
In my opinion, the heuristical approach, using machine learning techniques as a basis, will have great success in the near future for the detection and removal of unused code in large software systems.


